PROMOTERS
What are Promoters
Promoters are DNA sequences that define where transcription of a gene by RNA polymerase will begin. Promoter sequences are typically located directly upstream or at the 5' end of the transcription initiation site. RNA polymerase and the necessary transcription factors bind to the promoter sequence and initiate transcription. Promoter sequences define the direction of transcription and indicate which DNA strand will be transcribed; this strand is known as the sense strand.Many eukaryotic genes have a conserved promoter sequence called the TATA box, located 25 to 35 base pairs upstream of the transcription start site. Transcription factors bind to the TATA box and initiate the formation of the RNA polymerase transcription complex, which promotes transcription. A gene has three major regions: The promoter, coding region, and terminator (Fig.1). The promoter acts as the regulator for the level of gene expression i.e. when, where and how much of the gene product i.e protein is produced. The coding region contains the information for making mRNA, which in turn specifies the protein to be produced while the terminator indicates the end of the gene.

Fig: Major regions of a gene
Promoters regulate level of gene expression by specifying how many mRNAs are produced i.e transcribed for a given gene. The DNA sequence of the promoter region interacts with transcription factor proteins that serve to recruit the cellular machinery needed to produce the RNA transcripts. Transcription is performed by the enzyme, RNA polymerase. The resultant RNA transcript is processed into mRNA, and then translated into protein. The number of mRNAs produced is a primary factor determining the amount of protein synthesized, which plays a role in determining the level of gene expression.Factors that bind to promoters react to signals from the organism or/and the surrounding environment. The source and type of signal determines the type of promoters that are activated. In genetic engineering, there are three major types of promoters used, depending on the level of gene expression and specificity required:
1. Constitutive promoters: These promoters facilitate expression of the gene in all tissues regardless of the surrounding environment and development stage of the organism. Such promoters can turn on the gene in every living cell of the organism, all the time, throughout the organism’s lifetime. These promoters can often be utilized across species. Examples of constitutive promoters that are commonly used for plants include Cauliflower mosaic virus (CaMV) 35S, opine promoters, plant ubiquitin (Ubi), rice actin 1 (Act-1) and maize alcohol dehydrogenase 1 (Adh-1). CaMV 35S is the most commonly used constitutive promoter for high levels of gene expression in dicot plants. Maize Ubi and rice Act-1 are the currently the most commonly used constitutive promoters for monocots.
2.Tissue-specific or development-stage-specific promoters: These promoters facilitate expression of a gene in specific tissues or at certain stages of development while leaving the rest of the organism unmodified. In the case of plants, such promoters might specifically influence expression of genes in the roots, fruits, or seeds, or during the vegetative, flowering, or seed-setting stage. If the developer wants a gene of interest to be expressed in more than one tissue type for example the root, anthers and egg sac, then multiple tissue-specific promoters may have to be included in the gene construct.Effective gene expression in specific plant parts or development stages often has been observed when promoters from closely related species are used. There are many promoters in this category because they have different tissue and developmental specificities. An example of a tissue-specific promoter is the Phosphoenolpyruvate (PEP) carboxylase promoter which induces gene expression only in cells that are actively involved in photosynthesis.
3. Inducible promoters :These promoters are activated by exogenous (i.e., external) factors. Exogenous factors may be abiotic such as heat, water, salinity, chemical, or biotic like pathogen or insect attack. Promoters that react to abiotic factors are the most commonly used in plant genetic engineering because these can easily be manipulated. Such promoters respond to chemical compounds such as antibiotics, herbicides or changes in temperature or light. Inducible promoters can also be tissue or development stage specific.
4. Synthetic promoters : These promoters are DNA sequences that do not exist in nature and which are designed to regulate the activity of genes, controlling a gene’s ability to produce its own uniquely encoded protein.
Promoters can be derived directly from naturally occurring genes, or may be synthesized to combine regulatory sequences from different promoter regions. The promoters interact with other regulatory sequences (enhancers or silencers) and regulatory proteins (transcription factors) to influence the amount of gene transcription/expression.
There are number of methods available to isolate the promoters some of them are listed below
1.Screening of the genomic DNA library constructed from the mutant plant
2.Plasmid rescue
3.Inverse PCR (IPCR)
4.Genome Walking
5.Thermal asymmetric interlaced PCR (TAIL-PCR)
1. Screening of the genomic DNA library constructed from the mutant plant : T- DNA and transposable elements are used in the creation of mutant plants then DNA fragments flanking the T-DNA are identified from the library and used as a probe to isolate the wild type genomic sequence.The T-DNA disrupts the expression of the gene also it acts as a marker for subsequent identification of the mutation. In this method, large populations of tagged mutants are generated, which can then be screened for insertions in specific genes .Alternatively, the insertion tags can be individually sequenced and compiled in databases that can be searched for a gene disruption event of interest .This is becoming easier now as genomic sequences of many insertion sites are becoming available
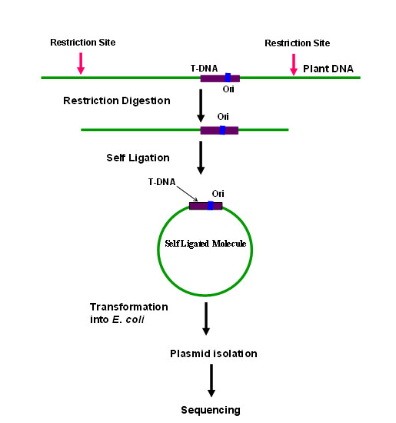
2. Plasmid rescue: Widely used method for obtaining sequence information about the T-DNA–gDNA junctions in the recipient genome .It is an approach which is employed in case the T-DNA construct consists of an antibiotic resistance gene and a bacterial origin of replication (ori) . The genomic DNA of mutant plant is subjected to complete digestion followed by ligation to circularize all the fragments and transform them into E. coli host. The plasmids isolated from the E. coli would be analyzed for the presence of T- DNA and the flanking plant DNA sequences
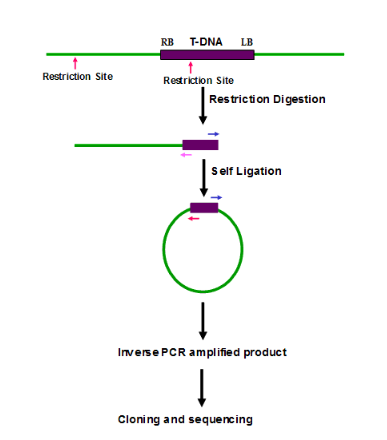
3. Inverse PCR (IPCR): It amplify the unknown sequence from the known sequence. Cleavage of genomic DNA by a suitable enzyme followed by ligation of the fragments to facilitate self-circularization. A set of nested primers derived from the T-DNA border regions are used to amplify the flanking DNA, cloned and sequenced and is specially useful in the amplifying and identifying flanking sequence of various genomic inserts
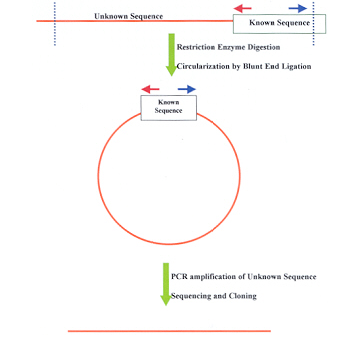
4. Genome Walking : Genome walking is a method to isolate flanking genomic segments (e.g. promoter regions) adjacent to a known sequence. Uncloned genomic DNA is digested with various restriction endonucleases.Ligated to long suppression adapters The desired genomic region is amplified with a primer specific to the outer part of the suppression adapter and a gene-specific primer . Since the adapters are long and the adapter-specific primer is short (the sufficient ratio is 40 to 20 base pairs) .The amplification of the whole pool from that single adapter-specific primer is effectively suppressed, and only the fragments of interest are generated during PCR. Both flanks of the known sequence – downstream as well as upstream – can be amplified, the direction depends exclusively upon the strand specificity of the gene-specific primer.
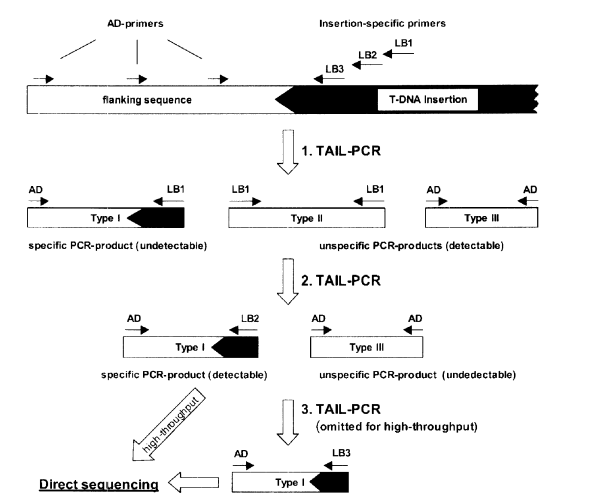
5.Thermal Asymmetric Interlaced PCR (TAIL-PCR) : Makes use of three nested T-DNA-specific primers in one end and a short arbitrary degenerate (AD) primer in the other end .Three different PCR reactions are performed with these primer sets. The primary PCR reaction involves different primer annealing temperatures and low and high stringent cycles to facilitate annealing of arbitrary and specific primers, respectively .This step results into both specific as well as nonspecific amplification of products.In the next two steps of PCR reactions the non-specific products are eliminated amplifying predominantly the T-DNA flanking genomic DNA
What are regulatory elements
Regulatory elements determine the connectivity of molecular networks and mediate a variety of regulatory processes at the transcriptional, post-transcriptional and post-translational levels. The first genetic regulatory mechanism uncovered came with Jacob and Monod’s 1961 discovery of the lac operon Since then, enormous efforts have gone into understanding how regulatory DNA encodes the instructions for controlling gene expression in situations ranging from development, response to stimuli and disease. Specific genomic regions broadly labeled as regulatory elements including promoters and enhancers are the primary regulatory components of the genome. They interact with site-specific transcription factors to establish cell type identity and regulate gene expression and are associated with specific, epigenetically established and maintained chromatin features such as histone modifications, DNA methylation and DNA looping. Since all genes including transcription factors themselves are governed by regulatory elements, interactions between transcription factors, co-factors and chromatin regulators with regulatory DNA at specific loci effectively establish molecular regulatory networks. The core functional unit of DNA regulatory elements are transcription factor binding sites (TFBS), and recent technological advances fueled by high-throughput DNA sequencing have greatly increased our ability to identify and characterize individual regulatory elements and TFBS sequences across a broad range of cell types, organs, species and disease states. In recent years, it has become increasingly clear that alterations in regulatory DNA are associated with disease. Moreover, a growing number of mutations, epigenetic aberrations and structural alterations in regulatory DNA have been implicated in the molecular pathogenesis of cancer. Here we review the different types of regulatory elements found in molecular networks, with a focus on regulatory DNA. We discuss the transcriptional and epigenetic networks that DNA regulatory elements mediate, identify technologies to uncover such elements, and discuss how such technologies and computational methods can be used to help identify the underpinnings of disease.
Molecular networks use a broad variety of regulatory elements
Regulatory elements are found at transcriptional and post-transcriptional levels and further enable molecular networks at those levels. For example, at the post-transcriptional level, the biochemical signals controlling mRNA stability, translation and subcellular localization are processed by regulatory elements. One such class, microRNA target sites, was discovered a little over a decade ago, and in fact preceded the discovery of microRNAs . Notable resources such as RegNetwork integrate experimental and computationally-based regulatory interactions, including those between TFs, microRNAs, and target genes. RNA binding proteins are another class of post-transcriptional regulatory elements and are further classified as sequence elements or structural elements. Specific sequence motifs that may serve as regulatory elements are also associated with mRNA modifications, for example m6A. Such motifs are then read by other proteins and lead to effects on stability and translation. Regulatory elements are also ubiquitous at the post-translational level, where short amino acid stretches mediate a broad variety of processes such as activation or deactivation via phosphorylation/dephosphorylation by a variety of kinases and phosphatases (phosphosites), subcellular localization (e.g. Nuclear Localization Signal), degradation (PEST signal, ubiquitination and sumoylation). Many such regulatory elements are involved in disease – some are directly mutated in diseases such as cancer (8). While the remainder of this review focuses on regulatory DNA, we note that a broad variety of regulatory elements exist which govern the activity of molecular networks at numerous cellular layers.A variety of DNA regulatory elements are involved in the regulation of gene expression and rely on the biochemical interactions involving DNA, the cellular proteins that make up chromatin, and transcription factors. Promoters and enhancers are the primary genomic regulatory components of gene expression. Promoters are DNA regions within 1–2 kilobases (kb) of a gene’s transcription start site (TSS); they contain short regulatory elements (DNA motifs) necessary to assemble RNA polymerase transcriptional machinery. However, transcription is often minimal without the contribution of DNA regulatory elements located more distal to the TSS. Such regions, often termed enhancers, are position-independent DNA regulatory elements that interact with site-specific transcription factors to establish cell type identity and regulate gene expression .The collection of TFs that bind enhancers ultimately stabilize or inhibit the activity of RNA polymerase II through mechanisms including recruitment of epigenetic enzymes that catalyze post-translational histone modifications, and recruitment of cofactors that promote DNA looping. It is most often the case that enhancers contain multiple regulatory elements, including composite elements, thus enabling cooperative and combinatorial regulation, and precise spatio-temporal patterns of expression. A recent study by Stampfel et al for example used enhancer complementation assays to systematically characterize the potential for different combinations of TFs to participate in combinatorial enhancer control.
Identifying enhancers and enhancer regulatory elements: is an active area of research and most often focuses on the mapping of putative enhancers through the integrating of information on post-translational histone modifications, DNA sequence, genomic localization, and nearby gene expression. Definitively identifying enhancers requires experimental evidence documenting the effect of increased gene expression, and most studies focus on putative enhancers. As evidenced by the small number enhancers that have definitive regulatory functions, identifying and characterizing enhancers has proven difficult. Multiple enhancers can act additively and redundantly to regulate gene expression .In addition, enhancers may act independently of their sequence context and at distances of several to many hundreds of kb from their target genes through a process known as looping . As a consequence of these features, it is difficult to identify putative enhancers and link them to their target genes on the basis of DNA sequence alone. Current strategies focus on identifying putative enhancers using computational and experimental approaches, and the critical integration of these disciplines, as discussed below.Clusters of enhancers that are occupied by “master regulator” TFs have been termed super-enhancers , however both the terminology and function of super-enhancers has been debated .Other types of distal regulatory elements include insulators, often bound by the protein CTCF.
Isolation of regulatory elements:
Understanding the regulation of transcription by sequence-specific regulatory factors and subsequent remodeling of chromatin is central to studies of health and disease. The activities of regulatory factors at promoters, enhancers, silencers and insulators typically cause nucleosomes to be evicted from chromatin in eukaryotic cells1. Therefore, one of the most effective means of discovering transcriptional regulatory elements is through the identification of nucleosome-depleted regions (‘open chromatin’). Historically, this was accomplished by exploiting regional hypersensitivity to nucleases such as DNase .More recently, we demonstrated an alternative methodology for the detection of open chromatin, which we termed FAIRE(Formaldehyde Assisted isolation of regulatory elements ). FAIRE was first characterized in yeast and subsequently applied to human cells and tissues The technique has proven useful for a wide range of eukaryotes, from Plasmodium to maize. Here we present recent method-ological enhancements that improve the utility and reliability of FAIRE, especially for use on tissues or lipid-laden cells such as adipocytes
Advantages of FAIRE
Antibody and enzyme independency: In contrast to ChIP, which is highly subject to antibody reliability and variability issues24, FAIRE offers the consistency of a chemical- based isolation. Moreover, FAIRE does not require enzymes, such as DNase or MNase, which are commonly used in ana-logous methods for detecting nucleosome-free regions. Avoiding the optimization and extra steps necessary for enzymatic processing or immunoprecipitations eliminates a major source of variation, and thus makes it a much more reliable and robust method.
Enhancer detection.: As described here and in Song et al., FAIRE may identify addi-tional transcriptional enhancers and other distal regulatory elements in comparison to other methods such as DNase-seq.
Sequenced input control not required :As discussed in Rashid et al., a sequenced input control is generally not required for proper analysis of FAIRE-enriched regions. This reduces next-generation sequencing costs as well as the cost of reagents.
Applicability to tissue samples : As FAIRE does not require a single-cell suspension or nuclear isolation, it is easily adapted for use on tissue samples. The only additional step needed is pulverization of frozen tissue into a coarse powder before fixation
Comments
Post a Comment